

Natural Language Processing Viva Questions (NLP Viva)

What is NLP?
The ability of a computer program to understand human language as it is spoken and written
List some Components of NLP?
Morphological and Lexical Analysis.
Syntactic Analysis.
Semantic Analysis.
Discourse Integration.
Pragmatic Analysis.
What are the different phases in NLP?
lexical (structure) analysis
parsing
semantic analysis
discourse integration
pragmatic analysis.
What is Lexical analysis?
It’s First stage and also known as morphological analysis
It involves identifying and analyzing structure of words
What is Syntactic analysis?
It’s also known as parsing and syntax analysis
Analysis that tells us the logical meaning of certain given sentences or parts of those sentences.
What is Semantic analysis?
semantic analysis is the process of drawing meaning from text.
The text is checked for the meaningfulness
What is Discourse integration?
It means a sense of the context.
Eg. Mena is girl she goes to school : she is dependency here
What is Pragmatic analysis?
It deals with outside word knowledge, which means knowledge that is external to the documents and/or queries.
E.g : open the book is interpreted as a request instead of an order
What is Phonology?
The study of sound patterns and their meanings, both within and across languages
Eg. : study of different sounds and the way they come together to form speech and words - such as the comparison of the sounds of the two "p" sounds in "pop-up."
List some areas of NLP?
Searching
Machine translation
Summarization
Named-Entity Recognition
Parts-of-Speech tagging (POS)
Information retrieval
Information grouping
Sentiment analysis
Define the NLP Terminology?
NLP Terminology is based on Weights and Vectors, Text Structure, Sentiment Analysis, Text Classification,Machine Reading.
Define: Ambiguity
The ability of being understood in more than one way
One word, one phrase, or one sentence can mean different things depending on the context
What are the types of ambiguities?
Lexical ambiguity - Words have multiple meanings.
Syntactic ambiguity - A sentence has multiple parse trees.
Semantic ambiguity - Related to sentence interpretation
Metonyy ambiguity - Most difficult. It deals with phrases
What is Lexical ambiguity?
Words have multiple meanings.
Eg. Backstage : Noun & Backdoor : Adjective
What is structural ambiguity?
the presence of two or more possible meanings within a single sentence or sequence of words.
Eg. The man saw the girl with the telescope”. It is ambiguous whether the man saw the girl carrying a telescope or he saw her through his telescope.
What is scope ambiguity?
an ambiguity that occurs when two quantifiers or similar expressions can take scope over each other in different ways in the meaning of a sentence.
Eg. ``Every man loves a woman. ''
What is Attachment ambiguity?
arises from uncertainty of attaching a phrase or clause to a part of sentence
Eg, old men and women” is ambiguous. Here, the doubt is that whether the adjective old is attached with both men and women or men alone.
What is semantic ambiguity?
when a word form corresponds to more than one meaning,
I don't like it when my father smokes.” The word “smokes” has more than one meaning
What is discourse ambiguity?
This kind of ambiguity occurs when a sentence is parsed in different ways
What is pragmatic ambiguity?
the situation where the context of a phrase gives it multiple interpretations
the words which have multiple interpretations
“I like you too” can have multiple interpretations like I like you (just like you like me), I like you (just like someone else dose).
List few challenges in NLP.
Synonyms
Ambiguity
Errors in text or speech
Idioms and slang
Domain specific language
Training Data
sarcasm
What is the significance of TF-IDF?
TF gives us information on how often a term appears in a document and IDF gives us information about the relative rarity of a term in the collection of documents
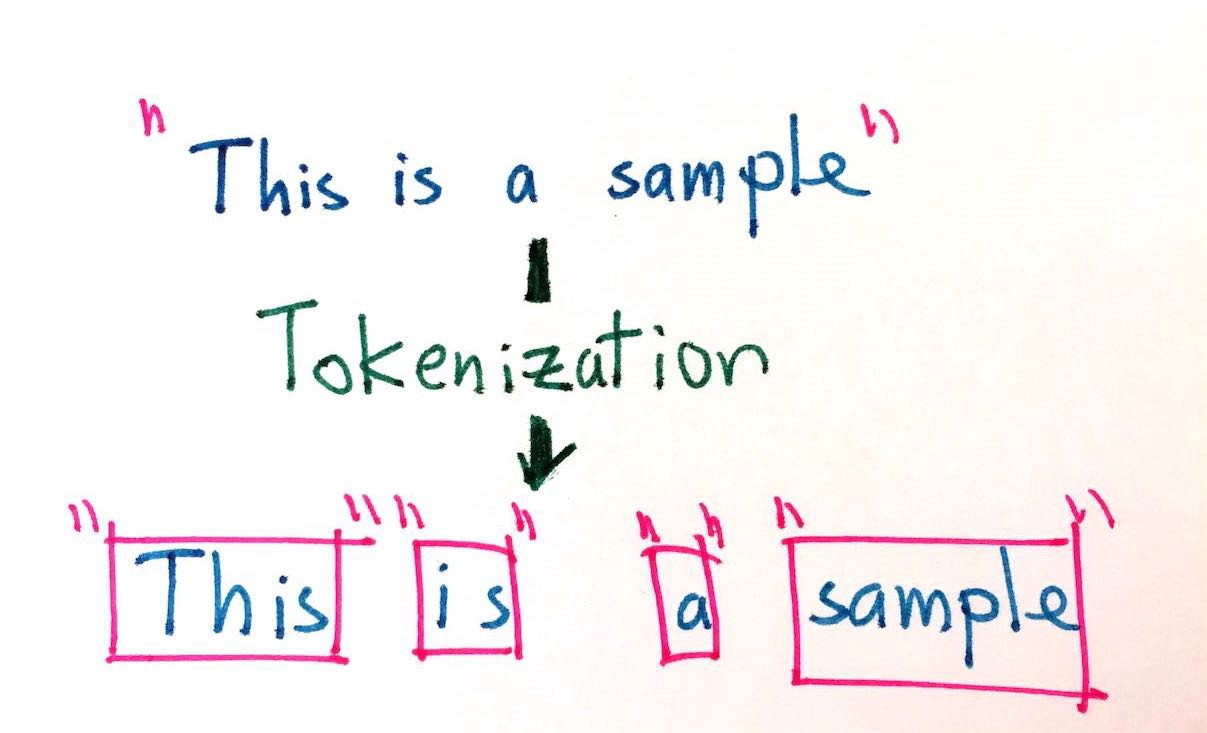
What is tokenization in NLP?
the process of tokenizing or splitting a string, text into a list of tokens.
What is NLTK?
a Python package that you can use for NLP
an amazing library to play with natural language
List some OpenSource Libraries for NLP?
NLTK - entry-level open-source NLP Tool
SpaCy - Data Extraction, Data Analysis, Sentiment Analysis, Text Summarization
AllenNLP - Text Analysis, Sentiment Analysis
GenSim - Document Analysis, Semantic Search, Data Exploration
What is the difference between NLP and NLU?
NLP focuses on processing the text in a literal sense, like what was said. Conversely, NLU focuses on extracting the context and intent, or in other words, what was meant.
What is the difference between NLP and CI (Conversational Interfaces)?
NLP is a kind of artificial intelligence technology that allows identifying, understanding and interpreting the request of users in the form of language.
CI is a user interface that mixes voice, chat and another natural language with images, videos or buttons.
List few differences between AI, Machine Learning, and NLP?
Machine learning focuses on creating models that learn automatically and function without needing human intervention.
NLP enables machines to comprehend and interpret written text.
An “intelligent” computer uses AI to think like a human and perform tasks on its own.
Define: Morphology
Morphology is the study of the internal structure of words.
Morphology focuses on how the components within a word (stems, root words, prefixes, suffixes, etc.
Name the classes of morphemes.
(a) bases (or roots) and (b) affixes.
List the types of affixes.
prefixes, infixes, and suffixes
What is concatenative morphology?
which is when two mor- phemes are ordered one after the other
What is non-concatenative morphology?
also called discontinuous morphology and introflection, is a form of word formation and inflection in which the root is modified and which does not involve stringing morphemes together sequentially.
What is inflectional morphology
the study of processes, including affixation and vowel change, that distinguish word forms in certain grammatical categories.
What is derivational morphology?
the process of creating new words from a stem/base form of a word
What is stemming in NLP?
the process of reducing a word to its word stem that affixes to suffixes and prefixes or to the roots of words known as a lemma.
What is Lemmatization in NLP?
Lemmatization is the process of grouping together the different inflected forms of a word so they can be analyzed as a single item.
What is the difference between Stemming and Lemmatization?
both generate the foundation sort of the inflected words and therefore the only difference is that stem may not be an actual word whereas, lemma is an actual language word. Stemming follows an algorithm with steps to perform on the words which makes it faster.
Define: Regular Expression
A regular expression is a sequence of characters that specifies a search pattern in text.
Define: Finite Automata
Finite automata or finite state machine is an abstract machine that has five elements or tuples.
Used to recognize patterns
What are the two views of FSAs?
deterministic finite-state machines and non-deterministic finite-state machines.
How can FSAs be used for natural language?
deciding whether a given word belongs to a particular language or not.
Define: NFSA
List the requirements to build a morphological parser.
use of a finite state transducer (FST), which inputs words and outputs their stem and modifiers.
Define: Lexicon
A lexicon is the vocabulary of a language or branch of knowledge.
Define: FST
A finite-state transducer is a finite-state machine with two memory tapes
List the uses of FST.
phonological and morphological analysis in natural language processing research and applications
What are Orthographic rules?
a Linguistic Expression Creation Rule that constraints the creation of a Written Expression
What is Porter Stemmer?
a process for removing the commoner morphological and inflexional endings from words in English.
Define: Consonant
A consonant is a sound made with your mouth fairly closed.
Define: Vowel
A vowel is a speech sound made with your mouth fairly open, the nucleus of a spoken syllable.
List steps of Porter Stemmer algorithm.
Define: Language models
a probability distribution over sequences of words
What are the types of Language models?
Statistical Language Models
Neural Language Models
Speech Recognization
Machine Translation
Sentiment Analysis
Define: Unigram
A 1-gram (or unigram) is a one-word sequenc
Define: Bigram
A bigram or digram is a sequence of two adjacent elements from a string of tokens, which are typically letters, syllables, or words.
Define: N-gram
N-grams are continuous sequences of words or symbols or tokens in a document
What is Intrinsic evaluation of Language models?
finding some metric to evaluate the language model itself, not taking into account the specific tasks it's going to be used for
What is Extrinsic evaluation of Language models?
evaluating the models by employing them in an actual task (such as machine translation) and looking at their final loss/accuracy.
Define: Perplexity
a measurement of how well a probability model predicts a sample
Define: Parts of Speech
process which refers to categorizing words in a text (corpus) in correspondence with a particular part of speech, depending on the definition of the word and its context.
What is part of speech (POS) tagging?
It is a process of converting a sentence to forms – list of words, list of tuples (where each tuple is having a form
Explain the different algorithms used in POS Tagging.
Viterbi algorithm, Brill tagger, Constraint Grammar, and the Baum-Welch algorithm (also known as the forward-backward algorithm)
Which are the categories of POS?
verb, noun, pronoun, adjective, adverb, preposition, conjunction, and interjection
What are Closed class POS?
the category of function words—that is, parts of speech (or word classes)—that don't readily accept new members.
What are Open class POS?
parts of speech (or word classes) that readily accept new members
Define: Nouns, Verbs, Adjectives, Adverbs, Interjections, Prepositions, Articles, Determiners,

Conjunctions, Pronouns,
Auxiliary verbs.
a verb that adds functional or grammatical meaning to the clause in which it occurs, so as to express tense, eg : am is are
Explain Penn treebank POS Tags?
CC Coordinating conjunction
DT Determiner
IN Preposition or subordinating conjunction
JJ Adjective
MD Modal
NN Noun, singular or mass
PDT Predeterminer
PRP Personal pronoun
RB Adverb
SYM Symbol
TO to
List the approaches for POS tagging?

Explain Rule based POS Tagging.
Rule-based taggers use dictionary or lexicon for getting possible tags for tagging each word
Explain Stochastic POS Tagging.
disambiguate words based solely on the probability that a word occurs with a particular tag
What is CFG?
formal grammar whose production rules are of the form. with a single nonterminal symbol, and a string of terminals and/or nonterminals
Explain Top down approach for derivation tree.
parse tree constructs from top and input will read from left to right.
Explain Bottom up approach for derivation tree.
starts evaluating the parse tree from the lowest level of the tree and move upwards for parsing the node
Explain Leftmost derivation of a string.
The process of deriving a string by expanding the leftmost non-terminal at each step
Explain rightmost derivation of a string.
the input is scanned and replaced with the production rule from right to left.
What is syntax?
the arrangement of words and phrases to create well-formed sentences in a language
What is Parsing?
process of analyzing a string of symbols
What is HMM?
a class of probabilistic graphical model that allow us to predict a sequence of unknown (hidden) variables from a set of observed variables.
Eg. Weather Prediction
How is HMM used for POS tagging?
The states in an HMM are hidden. In the part of speech tagging problem, the observations are the words themselves in the given sequence. As for the states, which are hidden, these would be the POS tags for the words.
What are the components of an HMM Tagger?
Q: Set of possible Tags.
A: The A matrix contains the tag transition probabilities P(ti|ti−1) which represent the probability of a tag occurring given the previous tag. ...
O: Sequence of observation (words in the sentence)
What is Viterbi algorithm?
a dynamic programming algorithm for obtaining the maximum a posteriori probability estimate of the most likely sequence of hidden states
What is Maximum Entropy Model?
the most appropriate distribution to model a given set of data is the one with highest entropy among all those that satisfy the constrains of our prior knowledge
What is CRF?
Conditional Random Fields (CRF) CRF is a discriminant model for sequences data similar to MEMM. It models the dependency between each state and the entire input sequences.
What is Lexical Semantics?
a subfield of linguistic semantics, is the study of word meanings.
What is Compositional semantics?
the construction. of meaning (generally expressed as logic) based on syntax.
Define: Lexeme
A lexeme is a unit of lexical meaning that underlies a set of words that are related through inflection
Define: Lexicon
A lexicon is the vocabulary of a language or branch of knowledge
Define: Lemma
the canonical form, dictionary form, or citation form of a set of words.
For example, runs, running, ran are all forms of the word run
Define: Sense
ability to determine which meaning of word is activated by the use of word in a particular context
Define: Dictionary
Commonly a dictionary consists of multiple items, with each item associated with multiple terms.
Define: Homonymy
the words having same spelling or same form but having different and unrelated meaning
What are homonyms?
each of two or more words having the same spelling or pronunciation but different meanings and origins.
Define: Polysemy
the capacity for a sign to have multiple related meanings.
For example, a word can have several word senses
What is Word Sense Disambiguation?
The problem of determining which "sense" (meaning) of a word is activated by the use of the word in a particular context
Define: Synonymy
words that are pronounced and spelled differently but contain the same meaning
What are synonyms?
a word or phrase that means exactly or nearly the same as another word or phrase
Define: Hyponymy
the relationship between a generic term and instances of that generic term
Define: Hypernymy
Hypernymy, or the is-a relation, is an important lexical relation for NLP tasks
What are hyponyms?
a word or phrase whose semantic field is more specific than its hypernym
What are hypernyms?
a term whose meaning includes the meaning of other words
What are homophones?
• Homophones: write and right, piece and peace
What are heteronyms?
a word that has a different pronunciation and meaning from another word but the same spelling
What are meronyms?
a term that specifies a part of something but that refers to the whole of the thing
example, the word hands in “needing more hands to finish the project,
What are antonyms?
a word of opposite meaning
Define: Declarative sentence
a sentence that makes a statement, provides a fact, offers an explanation, or conveys information
Define: Imperative sentence
a sentence that expresses a direct command, request, invitations, warning, or instruction
Define: Yes-No questions
also called closed questions because there are only two possible responses: Yes or No
Define: Wh-questions
Wh-questions begin with what, when, where, who, whom, which, whose, why and how. We use them to ask for information.
What is WordNet?
large lexical database of English
in which we have adjectives, adverbs, nouns, and verbs grouped differently into a set
Applications : - information retrieval, automatic text classification, automatic text summarization, machine translation
Define: Discourse
Discourse is spoken or written communication between people, especially serious discussion of a particular subject
Eg, Synonyms: conversation, talk, discussion
Define: Monologues
Monologue refers to a speech delivered by a character in order to express his thoughts and feelings to other characters or the audience.
Define: Dialogue
Dialogue refers to a conversation between two or more characters in a work of literature
What is reference resolution?
a process that accepts a term description and rewrites it to account for information available in the discourse context
Define: Reference
Reference is a relationship between objects in which one object designates, or acts as a means by which to connect to or link to, another object
Define: Referring Expression
An expression (typically a *noun phrase) used to identify a person, object, place, event, etc. Also called r-expression
Define: Referent
one that refers or is referred to especially : the thing that a symbol (such as a word or sign) stands for.
Define: Corefer
intransitive verb. : to compare views
Define: Antecedent
An antecedent is a part of a sentence that is later replaced by a pronoun. An example of an antecedent is the word “John” in the sentence: “John loves his dog.” Any thing that precedes another thing, especially the cause of the second thing.
Define: Anaphora
the repetition of words or phrases in a group of sentences, clauses, or poetic lines.
Define: Cataphora
The use of a grammatical substitute (such as a pronoun) that has the same reference as a following word or phrase
List the types of referring expressions.
Pronouns
Definite noun phrases
What are indefinite noun phrases?
a noun phrase that is an Indefinite Description Phrase
What are definite noun phrases?
a determined noun phrase whose head is a noun with definiteness.
For example "the park" in "We will go to the park"
What are pronouns?
A pronoun is a word that takes the place of or refers to a noun. You may recall that a noun is a word that names a person, place, thing,
Eg. he, she, you, me, I, we, us, this, them, that.
What are demonstratives?
used to indicate which entities are being referred to and to distinguish those entities from others.
Eg. the "near" demonstratives this and these, and the "far" demonstratives that and those.
What is one-anaphora?
anaphoric noun phrases headed by the word one
List the types of referents.
faces and objects. Within each referent type, six were known referents (i.e., faces of famous people and everyday objects) and six were unknown referents (i.e., faces of unknown people and novel objects).
What are inferrables?
to conclude (a state of affairs, supposition, etc) by reasoning from evidence
What are discontinuous sets?
he set of all points of discontinuity of a function may be a discrete set, a dense set, or even the entire domain of the function.
What are generics?
What are the syntactic and semantic constraints?

What is dependency parsing?
It refers to the process of examining the dependencies between the phrases of a sentence in order to determine its grammatical structure
Differentiate regular grammar and regular expression.
Regular grammar: It is a generator of regular language. A language which should generate all the strings from given language is called generator. For generating regular language we need some rules and that are defined in grammar. Grammar is embedded in compiler to check given source code.
–
Regular expression: It is representator of regular language. Regular expression is mathematically represent by some expression called regular expression. Regular expression is character sequence that define a search pattern.
List some tools for training NLP models?
NLTK - entry-level open-source NLP Tool Text classification - POS tagging -Tokenization
SpaCy - Data Extraction, Data Analysis, Sentiment Analysis, Text Summarization
GenSim - Document Analysis, Semantic Search, Data Exploration
TextBlob Library - Conversational UI, Sentiment Analysis
Explain Named entity recognition (NER)?
Named-entity recognition is a subtask of information extraction that seeks to locate and classify named entities mentioned in unstructured text into pre-defined categories such as person names, organizations, locations, medical codes, time expressions, quantities, monetary values, percentages, etc.
For example, in the sentence “Mark Zuckerberg is one of the founders of Facebook, a company from the United States” we can identify three types of entities: “Person”: Mark Zuckerberg “Company”: Facebook “Location”: United States
Which techniques can be used for keyword normalization in NLP, the process of converting a keyword into its base form?
Lemmatization and Stemming.
Which of the following techniques can be used to compute the distance between two-word vectors in NLP?
Distance between two-word vectors can be computed using Cosine similarity and Euclidean Distance.
Cosine Similarity establishes a cosine angle between the vector of two words. Cosine similarity closer to 1 between two-word vectors indicates the words are similar and vice-versa if it is closer to 0. The Euclidean distance between two points is the length of the shortest path connecting them.
What are the possible features of a text corpus in NLP?
Count of word in a document
Boolean feature – presence of word in a document
Vector notation of word
Part of Speech Tag
Basic Dependency Grammar (what is next word, previous word, next to next word, etc.)
Is Word End of Sentence or Beginning of Sentence
Length of word
Which of the text parsing techniques can be used for noun phrase detection, verb phrase detection, subject detection, and object detection in NLP?
Dependency Parsing and Constituency Parsing.
Dependency parsing is the process of analysing the grammatical structure of a sentence based on the dependencies between the words in a sentence.
Constituency Parsing is the process of analysing the sentences by breaking down it into sub-phrases also known as constituents
Does dissimilarity between words expressed using cosine similarity will have values significantly higher than 0.5?
True
Which techniques are keyword Normalization techniques in NLP?
Lemmatization and Stemming.
In a corpus of N documents, one randomly chosen document contains a total of T terms and the term “hello” appears K times. What is the correct value for the product of TF (term frequency) and IDF (inverse-documentfrequency), if the term “hello” appears in approximately one-third of the total documents?

In NLP, the algorithm decreases the weight for commonly used words and increases the weight for words that are not used very much in a collection of documents.
Inverse Document Frequency
In NLP, the process of removing words like “and”, “is”, “a”, “an”, “the” from a sentence is called as?
Removing stopwords
What does TF-IDF helps you to establish?
TF-IDF (Term Frequency - Inverse Document Frequency) is a handy algorithm that uses the frequency of words to determine how relevant those words are to a given document.
In NLP, how do you identify people, an organization from a given sentence, paragraph?
Named Entity Recognition
What are the pre-processing techniques in NLP?
Converting to lowercase
Removing extra whitespaces
Removing punctuations
Removal of stop words
Stemming and Lemmatization
What is BERT?
- BERT stands for Bidirectional Encoder Representations from Transformers. It is designed to pretrain deep bidirectional representations from unlabeled text by jointly conditioning on both left and right context. As a result, the pre-trained BERT model can be fine-tuned with just one additional output layer to create state-of-the-art models for a wide range of NLP tasks.
- BERT is pre-trained on a large corpus of unlabelled text including the entire Wikipedia (that’s 2,500 million words!) and Book Corpus (800 million words)
What is Naive Bayes algorithm, when we can use this algorithm in NLP?
- Naive Bayes is a family of probabilistic algorithms that take advantage of probability theory and Bayes’ Theorem to predict the tag of a text (like a piece of news or a customer review).
- They are probabilistic, which means that they calculate the probability of each tag for a given text, and then output the tag with the highest one.
- So Naïve Bayes is typically used for POS Tagging in NLP
What is text Summarization?
The process of shortening a set of data computationally, to create a subset that represents the most important or relevant information within the original content.
What is NLTK? How is it different from Spacy?
- NLTK is an open-source NLP library.
- NLTK was built by scholars and researchers as a tool to help you create complex NLP functions. It almost acts as a toolbox of NLP algorithms. In contrast, spaCy is similar to a service: it helps you get specific tasks done.
- NLTK was created to support education and help students explore ideas. SpaCy, on the other hand, is the way to go for app developers.
What is information extraction?
Information extraction is the task of automatically extracting structured information from
unstructured and/or semi-structured machine-readable documents and other electronically
represented sources.
What is Bag of Words?
- Machine learning algorithms cannot work with raw text directly; the text must be converted into numbers. Specifically, vectors of numbers. This is called feature extraction or feature encoding.
- A bag-of-words model, or BoW for short, is a way of extracting features from text for use in
modelling.
- It is called a “bag” of words, because any information about the order or structure of words in the document is discarded. The model is only concerned with whether known words occur in the document, not where in the document.
- The intuition is that documents are similar if they have similar content. Further, that from the
content alone we can learn something about the meaning of the document.
What are stop words?
Stopwords are the words in any language which does not add much meaning to a sentence. They can safely be ignored without sacrificing the meaning of the sentence.
Examples of stopwords in English, “and”, “a”, “have”, “has”, “it”, etc.
What are the steps involved in solving an NLP problem?
Lexical Analysis -> Syntax Analysis -> Semantic Analysis -> Discourse Analysis -> Pragmatic Analysis
What are the metrics used to test an NLP model?

How would you make a sentiment classifier?
- Collect text corpus that has documents/sentences that are tagged with correct sentiment.
- Pre-process the text data in the corpus using various techniques.
- Extract features for each input document/sentence in the corpus, examples of features could be POS Tags, length of words, next word, previous word, etc.
- Split the corpus into train and test data.
- Train the train data on a variety of classification algorithms.
- Evaluate performance of various algorithms on the test data using the Accuracy metric.
How can we handle misspellings for text input?
- By looking at words in the input that can be possible misspellings and computing the distance between that word and various other words in the dictionary in order to find a match.
- The closer the two words are (possible misspelled word and a random word in the dictionary), the more likely it is that that misspelled word’s match has been found.
- This distance is typically computing using the Levenshtein Distance metric.
- The Levenshtein distance between two words is the minimum number of single-character edits (i.e. insertions, deletions or substitutions) required to change one word into the other.
Give examples of anaphora
- It is the reference to an entity that has been previously introduced in the discourse and the
referring expression used is called anaphoric expression.
Example, “John went to Bill’s car dealership to check out an Acura Integra. He looked at it for about an hour.”
Here, “he” is an anaphora as it refers to “John”, “it” is an anaphora as it refers to “Acura Integra”.
Give examples of cataphora
- It is the reference to an entity that will be introduced in a later word or phrase.
- Example, “Despite his struggles, Ganesh soared to bigger heights.”
Here, “his” refers to “Ganesh” but the entity “Ganesh” hadn’t been introduced yet which is why “his” becomes a cataphora
What are split antecedents?
- It is t- More than one antecedent being referred to by a single proform (cataphora or anaphora) makes the set of antecedents as split antecedents.
- Example, “Ram told Shyam to attend the lecture. They went to the class together.”
Here, “Ram” and “Shyam” are antecedents and “They” is the proform (anaphora in this case). So more than one antecedent is referenced using a single proform, hence it is a split antecedent. he reference to an entity that will be introduced in a later word or phrase.
- Example, “Despite his struggles, Ganesh soared to bigger heights.”
Here, “his” refers to “Ganesh” but the entity “Ganesh” hadn’t been introduced yet which is why “his” becomes a cataphora.
What are coreffering noun phrases?
- When both antecedent and proform (cataphora or anaphora) are noun phrases then such referring expressions are called as co-referring noun phrases.
- Example, “The project manager is refusing help. The jerk only thinks of himself.”
Here, “The project manager” is antecedent and “The jerk” is proform and they both are Noun
Phrases.
Explain Hobb’s Algorithm.

Why coreference resolution is hard?
Because of the inherent ambiguity involved with Natural Languages
Explain the difference between Coreference and Anaphora.
- Coreference occurs when two or more expressions in a text refer to the same person or entity.
- Anaphora is a reference to an entity that has been previously introduced in the discourse.
- So anaphora is a special type of coreference.
What is Deixis? Explain different types of Deictics.

What is Implicature?

What is presupposition?

What is sequence labelling? Where is sequence labelling used?
- Sequence labelling is a typical NLP task which assigns a class or label to each token in a given input sequence.
- POS Tagging and Named Entity Recognition both are forms of sequence labelling tasks.
What are the issues in syntax analysis?

What are the different applications of N-gram?
Auto-completion of sentences, auto spell-check, and semantic analysis.
Different applications of NLP
Machine translation
Information retrieval
QA Answer system
Categorization
Summarization
Sentiment Analysis


